Stoga je vreme izvrsavanja binarnog pretrazivanja proporcionalno sa log n, pa kazemo da je ovo O(log n) algoritam.
| Strukture podataka i algoritmi |
| 4 Pretrazivanje |
Racunarski sistemi se cesto koriste za skladistenje velikih kolicina podataka
u kojima moraju da se nadju individualni slogovi u skladu sa nekim
kriterijumom pretrazivanja. Stoga su veoma vazni efikasni nacini
za skladistenje podataka koji omogucavaju brzu pretragu.
U ovoj glavi, proucicemo performanse nekih algoritama za pretrazivanje i
struktura podataka koje oni koriste.
Ako postoji n objekata u nasem skupu - bili oni smesteni kao niz
ili kao povezana lista - tada je ocigledno da u najgorem slucaju,
kada ne postoji objekat u skupu koji odgovara trazenom kljucu,
moramo da napravimo n poredjenja datog kljuca
sa kljucevima objekata u skupu.
Da bismo pojednostavili analizu i poredjenje algoritama,
posmatramo samo dominantnu operaciju i
brojimo koliko puta mora da se izvrsi dominantna operacija.
U slucaju pretrazivanja, dominantna operacija je poredjenje,
i posto pretrazivanje zahteva n poredjenja u najgorem slucaju,
kazemo da je ovo
O(n)
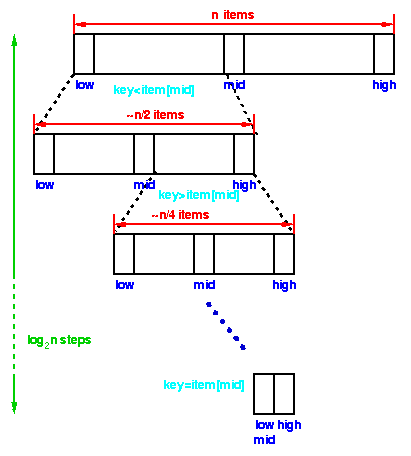
U binarnom pretrazivanju, najpre poredimo dati kljuc sa objektom na sredini niza.
Ako je to trazeni objekat, mozemo da se vratimo istog trenutka.
Ako je kljuc manji od kljuca objekta na sredini,
tada trazeni objekat mora da se nalazi u donjoj polovini niza;
ako je veci, tada trazeni objekat mora da se nalazi u gornjoj polovini niza.
Stoga, proceduru ponavljamo na donjoj (ili gornjoj) polovini niza.
Nasa FindInCollection
funkcija sada moze da se implementira ovako:
4.1 Sekvencijalno pretrazivanje
Da najpre ispitamo koliko vremena treba da pronadjemo objekat
koji odgovara zadatom kljucu u skupovima koje smo dosad razmatrali.
Zainteresovani smo za:
Medjutim, u najvecem broju slucajeva bavicemo se vremenom u najgorem slucaju,
s obzirom da proracuni bazirani na takvom vremenu vode do procena
zagarantovanih performansi. Sem toga, vreme u najgorem slucaju je obicno
lakse izracunati nego prosecno vreme.
4.2 Binarno pretrazivanje
Ako nase objekte stavimo u niz i
sortiramo ih bilo u rastuci ili opadajuci poredak po kljucu,
tada mozemo da dobijemo mnogo bolje performanse
pomocu algoritma koji se zove binarno pretrazivanje.
static void *bin_search( collection c, int low, int high, void *key ) {
int mid;
/* Uslov prekida */
if (low > high) return NULL;
mid = (high+low)/2;
switch (memcmp(ItemKey(c->items[mid]),key,c->size)) {
/* Slaganje, nasli smo objekat */
case 0: return c->items[mid];
/* kljuc je manji od mid, pretrazi donju polovinu */
case -1: return bin_search( c, low, mid-1, key);
/* kljuc je veci od mid, pretrazi gornju polovinu */
case 1: return bin_search( c, mid+1, high, key );
default : return NULL;
}
}
void *FindInCollection( collection c, void *key ) {
/* Trazi objekat u skupu
Pre-uslov:
(c je skup kreiran pozivom ConsCollection) &&
(c je sortiran u rastuci poredak po kljucu) &&
(key != NULL)
Post-uslov: vraca objekat identifikovan kljucem ako postoji,
u suprotnom vraca NULL
*/
int low, high;
low = 0; high = c->item_cnt-1;
return bin_search( c, low, high, key );
}
Primetimo:
static smanjuje vidljivost funkcije
i treba je koristiti kad god je moguce da bi se kontrolisao pristup funkcijama!
Analiza
|
|
Svaki korak algoritma deli pretrazivani podniz objekata na dva dela.
Skup od n objekata mozemo da delimo na pola
najvise log2 n puta.
Stoga je vreme izvrsavanja binarnog pretrazivanja proporcionalno sa log n, pa kazemo da je ovo O(log n) algoritam. |
|
Binarno pretrazivanje zahteva slozeniji program
nego nase originalno pretrazivanje,
pa zato za male vrednost n
ono moze da se izvrsava sporije nego jednostavno sekvencijalno pretrazivanje.
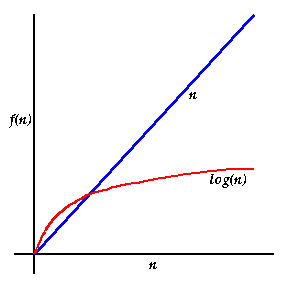
Medjutim, za dovoljno veliko n, Stoga, za veliko n, log n je mnogo manji od n, pa je i O(log n) algoritam mnogo brzi od O(n) algoritma. |
|
Analizu ponasanja algoritma cemo ispitivati formalnije u kasnijoj glavi. Najpre, da vidimo sta mozemo da uradimo sa operacijom (AddToCollection) dodavanja objekta u skup.
U najgorem slucaju, dodavanje moze da zahteva n operacija za ubacivanje u sortiran niz.
Slicna analiza pokazuje da je brisanje objekata takodje O(n) operacija.
Ako je nas skup statican, tj. ne menja se veoma cesto - ako se uopste i menja - tada ne moramo da se brinemo oko vremena potrebnog za menjanje njegovog sadrzaja: mozemo da se pripremimo da ce inicijalno postavljanje skupa i povremena dodavanja i brisanja trajati neko vreme. Zauzvrat, moci cemo da koristimo jednostavnu strukturu podataka (niz) koji ne koristi suvisnu memoriju.
Medjutim, ako je nas skup veliki i dinamican, tj. objekti se stalno dodaju i brisu, tada mozemo da dobijemo znacajno bolje performanse koristeci strukturu podataka poznatu kao stablo.
Kljucni pojmovi |
|
Dalje na Stabla Nazad na Sadrzaj |